
Generative engines now decide which brands surface when buyers ask bottom-of-funnel questions, and the gravity of that shift is redefining growth playbooks across categories where consideration once started with blue links and ended with demos. Today, recommendation share inside AI assistants concentrates around brands that present unmistakable category clarity and accumulate credible third-party proof, while purely technical maneuvers fade into background hygiene. This analysis maps the dynamics behind that reordering and shows how market influence is accruing to organizations that orchestrate a consistent narrative across owned and earned surfaces.
Market Context and Purpose
The practical outcome most commercial teams care about is simple: when an assistant is asked for the best solution for a clear job to be done, which brands are suggested first. GEO—generative engine optimization—exists to shape that outcome, yet it behaves less like classic SEO and more like reputation management fused with category strategy. The aim of this analysis is to clarify which levers actually move recommendation share, where the ceiling is set by ecosystem validation, and how teams should invest to capture durable gains.
Relevance is high because LLMs synthesize webwide signals, then normalize claims by weighting consensus over isolated assertions. As a result, smart formatting or schema alone rarely unlock inclusion. Instead, models favor brands whose positioning matches how third parties describe the category, whose reviews and analyst notes are credible, and whose communities echo the same value narrative. The purpose here is to translate those mechanics into a market-facing framework complete with operating metrics and a forward view.
Structural Shift: From Blue Links to Webwide Consensus
Traditional search created leverage on owned surfaces; metadata control, site architecture, and content depth could outrun rivals with enough discipline. The generative layer changed the baseline by blending grounded retrieval with corpus-level synthesis, which smooths outliers and amplifies corroborated claims. That normalization redistributes advantage from isolated on-site strength to a more complex mesh of reputation, category fit, and third-party authority.
Correlations between strong organic visibility and LLM citation frequency persist, indicating grounded search continues to influence which sources inform answers. However, citations function as a waypoint rather than a finish line. Many brands are cited for context but not recommended, particularly in categories governed by affiliates, marketplace reviews, and analyst bench tests. The implication is clear: technical strength lifts discoverability, but recommendation inclusion depends on whether the wider web already recognizes the brand as a leading fit for specific buyers and use cases.
These background developments matter because they redefine where investment returns peak. Once crawlability, indexation, and rendering are sound, upside shifts to ecosystem influence. That includes shaping how review sites frame capabilities, how analyst reports classify segments, and how real users articulate trade-offs—signals that models increasingly treat as decisive.
Where Recommendation Share Gets Decided
Consensus Over Tactics: Why Hacks Underperform
Market chatter has promoted quick fixes—AI info hubs, rigid markdown conversions, llms.txt files, FAQ stuffing, and heavy “key takeaways” scaffolding—as shortcuts to LLM favor. These tactics may ease parsing and improve human scanning, but they do not alter the model’s core judgment: who best fits the query’s intent within a defined category. Engines triangulate from multiple reputable surfaces and discount self-referential claims, which blunts the power of isolated on-site tricks.
Operationally, hacks create a false-positive signal of progress because they are easy to ship and easy to measure. Yet the incremental lift is typically capped unless those changes reinforce a larger, consistent story that third parties repeat. The market evidence points in one direction: sustained gains come from building a reputation that cannot be ignored when the model synchronizes editorial, review, and community perspectives.
Category Fit and Positioning Consistency: The New Advantage Curve
LLMs classify brands by reading homepage narratives, product taxonomies, pricing pages, comparative content, and who each vendor says it serves—then cross-checking that view against analysts, publishers, forums, and social proof. If any of those surfaces conflict, the model hedges, which reduces the probability of clear recommendations. In other words, ambiguity taxes inclusion.
Table stakes show their limits under scrutiny. FAQs add value only when they relieve real buyer anxieties; boilerplate is noise. “Key takeaways” can speed reading but rarely change classification. Over-structuring for machine readability bloats pages without reshaping model inference. And synthetic Reddit activity is self-defeating; moderators and user sentiment create durable records that engines weigh. By contrast, brands that align on-site positioning with the same category language found on review platforms and credible media tend to score higher on inclusion for well-defined jobs to be done.
Third-Party Proof: The Decisive Input, Misread Too Often
In competitive markets, affiliates, top publishers, analyst firms, marketplaces, and community threads heavily influence perceived fit. Engines look to those surfaces to test claims and prioritize who appears as a top pick. This is where misconceptions proliferate. Citations are not recommendations; appearing in an answer’s footnotes does not guarantee being named among the best options. Listicles do not brute-force outcomes either; models normalize them and elevate brands with broad corroboration.
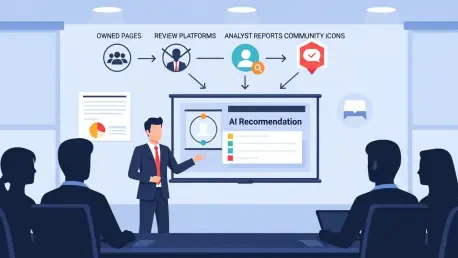
Categories also differ widely. Some are vendor-led with strong first-party documentation; others are governed by reviewers and analysts. Diagnosing the influence map before setting strategy is vital. Treat PR, partnerships, analyst relations, and customer marketing as GEO levers, not peripheral functions. When these teams reinforce a shared narrative, engines resolve ambiguity faster and reward the brand with inclusion more often.
Forward View: Normalization, Ecosystem Power, and Real-Voice Signals
The direction of travel favors broader consensus signals and devalues isolated tactics. Expect retrieval pipelines to privilege sources with transparent methods, consistent editorial standards, and traceable provenance. That tilt boosts the weight of established publishers, methodical testers, and review platforms with robust verification, further intertwining GEO with media quality and marketplace governance.
Economically, affiliate ecosystems and marketplaces continue to shape commercial discovery because they convert attention into revenue with measurable intent. Generative systems integrate these surfaces to infer buyer-fit patterns at scale, which concentrates influence among partners capable of proving outcomes. Meanwhile, community platforms retain clout as engines learn to interpret moderator actions, user karma, and longitudinal sentiment. Authentic voice becomes a durable asset, while manipulation triggers long-term penalties as models incorporate enforcement history.
Prediction bands point to a compounding effect: brands with sharp category definitions and multi-surface validation keep widening their lead as engines require less prompting to land on the same conclusion. Conversely, ambiguous positioning gets filtered out more aggressively, squeezing mid-tier players into niche use cases unless they invest in clearer narrative and external proof.
Strategy Playbook and Operating Metrics
A practical operating system emerges from these trends. First, diagnose model perception by prompting representative bottom-of-funnel queries: note whether the brand is recommended, how it is categorized, and which sources drive the answer. This yields a gap map between desired positioning and inferred reality. Second, chart influence surfaces across owned pages, earned media, partners and affiliates, and communities. The result should show where to concentrate effort based on category norms rather than generic best practices.
Third, align the narrative. Use the same category and buyer-job language across homepage, solutions, pricing, and comparisons, then ensure that vocabulary appears in analyst notes, top publisher reviews, and marketplace listings. Publish transparent comparisons that mirror how the space is already described outside the brand’s walls. Fourth, earn third-party proof that lasts: target credible reviewers, secure analyst inclusion, build integrations and partnerships that warrant coverage, and mobilize customer advocacy where moderation is strong and discourse is trusted.
Measurement needs to evolve as well. Recommendation inclusion is the headline metric, followed by category placement accuracy and buyer-fit alignment reflected in generated answers. Track citation volume and source mix as support, not as end goals. Monitor shifts in how engines summarize differentiators and whether those match the intended narrative. Maintain technical hygiene—crawlability, indexation, rendering, internal linking—to remove retrieval friction; once basics are sound, allocate marginal budget to ecosystem influence rather than formatting folklore.
Closing Perspective
This analysis showed that GEO success hinged on building consensus across the web rather than gaming page structure, and that recommendation share accrued to brands with crisp category definitions reinforced by credible third parties. It highlighted how engines discounted isolated claims, normalized listicles, and leaned on review platforms, analysts, and communities to arbitrate fit. It also mapped an operating system that prioritized perception diagnostics, influence-surface mapping, narrative alignment, third-party proof, and evolved measurement.
Strategically, the next moves were clear. Companies tightened positioning to reduce model hedging, invested in partnerships that produced testable outcomes, and shifted reporting from citation counts to recommendation inclusion and buyer-fit alignment. Teams treated technical hygiene as infrastructure, then funneled marginal effort into authoritative reviews, analyst coverage, and authentic community voice. Brands that executed this cross-functional approach found that generative engines rewarded them with stable, repeatable presence in high-intent answers, turning reputation clarity into a durable demand advantage.